
Data • Lit
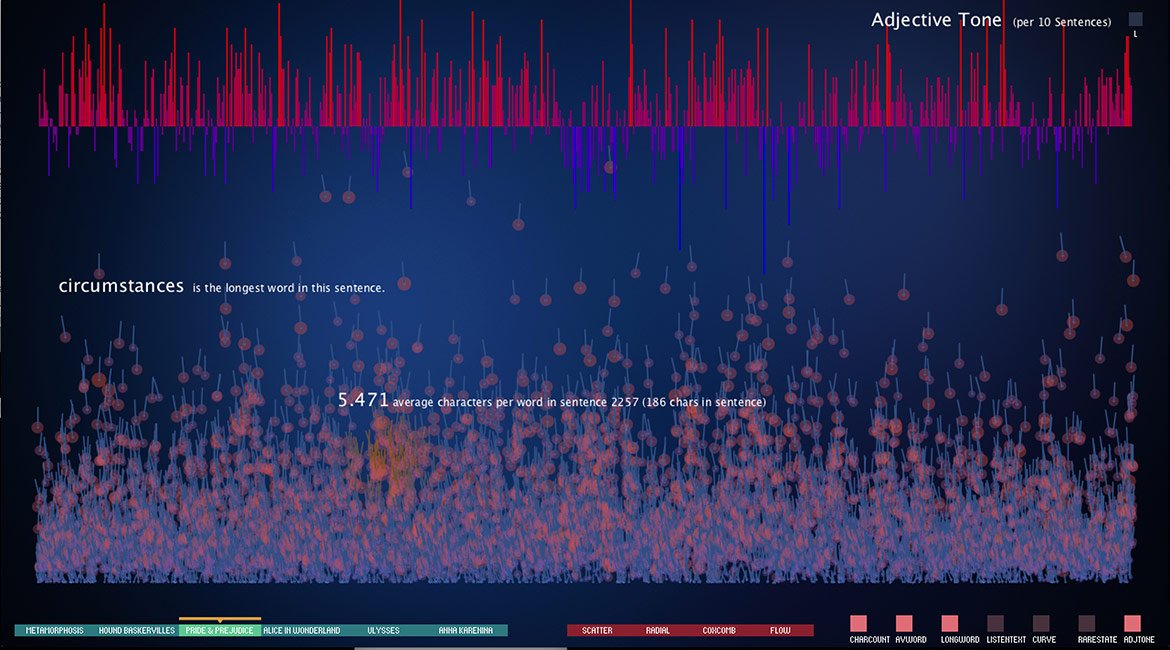
This piece of custom software uses entire novels as data-sets and extracts patterns in the language used by each author. By analyzing and visualizing vast quantities of written language, visual snapshots (or linguistic impressions) about a book are distilled into a single image. Data visualization techniques are used to display patterns in each book. An exciting outcome of the project is to use the text analysis to find patterns in a book and map them to corollary music theory analysis patterns in classical music. It then becomes possible to exploit shared themes between author and composer – to “hear Kafka through Mozart” or “hear Satie through Austen”.
Project Details
Medium: Interactive software (written in Processing), midi audio samples.
Completed December 2015



About
To think of a novel or piece of literature as data requires a leap. Whereas mathematically processing numbers through algebra is a simple task, trying to quantify aspects of written language is more challenging.
One technique employed to find out how rare a word is, compared to usage of today’s language. This is possible by cross-referencing a list of Google’s “Trillion Word Corpus” where the 10,000 most words are listed in order of commonality. By cross-checking each word with those most common 10,000 words, it is possible to assign a value of ‘rareness’ of each word used by a historical author.










